
Какие бывают виды выписок из ЕГРН, и в каких случаях они могут потребоваться?
Понедельник, 24 апреля
06:00 Мультимир (6+)
07:00 Доброе утро, Губкинский! (12+)
08:20 Большой скачок (12+)
08:45 Вместе в космос (12+)
09:10 Шефы и их тайны (12+)
09:35 Великие реки России (12+)
10:05 Больше, чем любовь (16+)
10:45 Т/с «Наследники» (12+)
11:30 Т/с «Пока станица спит» (12+)
13:00 Новости (16+)
13:20 Невредные заметки (16+)
13:40 Дело № (16+)
14:10 Т/с «Таинственная страсть» (16+)
15:00 Т/с «Мама-детектив» (16+)
15:55 Т/с «Практика» (16+)
17:40 Т/с «Год в Тоскане» (16+)
19:10 Невредные заметки (16+)
19:30 Новости (16+)
19:50 Т/с «Я рядом» (16+)
21:15 Х/ф «Тариф «Счастливая семья» (16+)
22:45 Д/ф «Офицеры» (16+)
23:55 Невредные заметки (16+)
00:15 Новости (16+)
00:35 Т/с «Обучаю игре на гитаре» 1 серия (16+)
01:20 Т/с «Обучаю игре на гитаре» 2 серия (16+)
02:00 Т/с «Обучаю игре на гитаре» 3 серия (16+)
02:45 Т/с «Обучаю игре на гитаре» 4 серия (16+)
03:25 Х/ф «Ты есть…» (16+)
05:00 Новости (16+)
05:20 Библейский сюжет (16+)
05:45 Архивы истории (12+)
Вторник, 25 апреля
06:00 Мультимир (6+)
07:00 Доброе утро, Губкинский! (12+)
08:20 Большой скачок (12+)
08:45 Вместе в космос (12+)
09:10 Шефы и их тайны (12+)
09:35 Великие реки России (12+)
10:05 Больше, чем любовь (16+)
10:45 Т/с «Наследники» (12+)
13:00 Новости (16+)
13:20 Актуальное интервью (12+)
13:40 Дело № (16+)
14:10 Т/с «Таинственная страсть» (16+)
15:00 Т/с «Мама-детектив» (16+)
15:55 Т/с «Практика» (16+)
17:40 Т/с «Год в Тоскане» (16+)
19:10 Актуальное интервью (12+)
19:30 Новости (16+)
19:50 Т/с «Я рядом» (16+)
21:25 Х/ф «Любовь на два полюса» (16+)
22:55 Д/ф «Победоносец.
 Фильм Аркадия Мамонтова» (16+)
Фильм Аркадия Мамонтова» (16+)23:40 Архивы истории (12+)
23:55 Актуальное интервью (12+)
00:15 Новости (16+)
00:35 Т/с «В плену у лжи» 1 серия (16+)
01:20 Т/с «В плену у лжи» 2 серия (16+)
02:05 Т/с «В плену у лжи» 3 серия (16+)
02:45 Т/с «В плену у лжи» 4 серия (16+)
03:45 Х/ф «Дачная поездка сержанта Цыбули» (16+)
05:00 Новости (16+)
05:20 Библейский сюжет (16+)
05:45 Архивы истории (12+)
Среда, 26 апреля
06:00 Мультимир (6+)
07:00 Доброе утро, Губкинский! (12+)
08:20 Большой скачок (12+)
08:45 Вместе в космос (12+)
09:10 Шефы и их тайны (12+)
09:35 Великие реки России (12+)
10:05 Больше, чем любовь (16+)
10:45 Т/с «Наследники» (12+)
11:30 Т/с «Пока станица спит» (12+)
13:00 Новости (16+)
13:20 Пурнефтегаз (12+)
13:40 Дело № (16+)
14:10 Т/с «Таинственная страсть» (16+)
15:00 Т/с «Мама-детектив» (16+)
15:55 Т/с «Практика» (16+)
19:10 Пурнефтегаз (12+)
19:30 Новости (16+)
19:50 Т/с «Чао, Федерико!» (16+)
21:20 Х/ф «Почти знаменит» (16+)
23:05 Д/ф «Гатчинский дворец» (6+)
23:55 Пурнефтегаз (12+)
00:15 Новости (16+)
00:35 Т/с «Я рядом» 1 серия (16+)
01:15 Т/с «Я рядом» 2 серия (16+)
02:00 Т/с «Я рядом» 3 серия (16+)
02:45 Т/с «Я рядом» 4 серия (16+)
03:30 Х/ф «Спешите любить» (16+)
05:00 Новости (16+)
05:20 Библейский сюжет (16+)
05:45 Архивы истории (12+)
Четверг, 27 апреля
06:00 Мультимир (6+)
07:00 Доброе утро, Губкинский! (12+)
08:20 Большой скачок (12+)
08:45 Вместе в космос (12+)
09:35 Великие реки России (12+)
10:05 Больше, чем любовь (16+)
10:45 Т/с «Наследники» (12+)
11:30 Т/с «Пока станица спит» (12+)
13:00 Новости (16+)
13:20 Будьте здоровы (12+)
13:40 Дело № (16+)
14:10 Д/ф «Илья Старинов.
 Личный враг Гитлера» (16+)
Личный враг Гитлера» (16+)15:00 Т/с «Мама-детектив» (16+)
15:55 Т/с «Практика» (16+)
17:40 Т/с «Год в Тоскане» (16+)
19:10 Будьте здоровы (12+)
19:30 Новости (16+)
19:50 Т/с «Чао, Федерико!» (16+)
21:20 Х/ф «Тариф «Счастливая семья» (16+)
22:50 Д/ф «Война и мир Михаила Калашникова» (16+)
23:35 Архивы истории (12+)
23:55 Будьте здоровы (12+)
00:15 Новости (16+)
00:35 Х/ф «Дачная поездка сержанта Цыбули» (16+)
01:50 Федерация (16+)
02:00 Т/с «Чао, Федерико!» 1 серия (16+)
02:45 Т/с «Чао, Федерико!» 2 серия (16+)
03:30 Т/с «Чао, Федерико!» 3 серия (16+)
04:15 Т/с «Чао, Федерико!» 4 серия (16+)
05:00 Новости (16+)
05:20 Библейский сюжет (16+)
05:45 Архивы истории (12+)
Пятница, 28 апреля
06:00 Мультимир (6+)
07:00 Доброе утро, Губкинский! (12+)
08:20 Большой скачок (12+)
08:45 Вместе в космос (12+)
09:10 Шефы и их тайны (12+)
09:35 Великие реки России (12+)
10:05 Больше, чем любовь (16+)
10:45 Т/с «Наследники» (12+)
11:30 Т/с «Пока станица спит» (12+)
13:00 Новости (16+)
13:40 Дело № (16+)
14:10 Д/ф «Война и мир Михаила Калашникова» (16+)
15:00 Т/с «Мама-детектив» (16+)
15:55 Т/с «Практика» (16+)
17:40 Т/с «Год в Тоскане» (16+)
18:40 А что у вас? (12+)
19:30 Новости (16+)
19:50 Х/ф «Отец поневоле» (16+)
21:25 Х/ф «Переписать любовь» (16+)
23:05 Х/ф «Кровавая леди Батори» (16+)
01:05 Х/ф «Спешите любить» (16+)
02:35 Концерт Михаила Бублика «Жизнь за два часа» (16+)
04:30 Человек на своем месте (12+)
05:00 Новости (16+)
05:20 Библейский сюжет (16+)
05:45 Архивы истории (12+)
Суббота, 29 апреля
06:00 Мультимир (6+)
07:30 И в шутку, и всерьёз (12+)
07:55 Д/ф «Илья Старинов.
08:40 Д/ф «Тайны космоса» (12+)
09:25 А что у вас? (12+)
09:45 БлинКом (16+)
10:35 М/ф «Птицы, как мы» (6+)
11:50 Х/ф «Озеро героев» (6+)
13:00 Х/ф «Сокровища Ермака» (6+)
14:30 Х/ф «Жандарм из Сен-Тропе» (16+)
16:05 Т/с «Синдром шахматиста» 1 серия (16+)
16:50 Т/с «Синдром шахматиста» 2 серия (16+)
17:35 Т/с «Синдром шахматиста» 3 серия (16+)
18:20 Т/с «Синдром шахматиста» 4 серия (16+)
19:05 Х/ф «Вне времени» (16+)
20:50 Х/ф «Путь к сердцу мужчины» (16+)
22:20 Т/с «Вспоминая тебя» 1 серия (16+)
23:10 Т/с «Вспоминая тебя» 2 серия (16+)
23:55 Т/с «Вспоминая тебя» 3 серия (16+)
01:30 Концерт Ёлки (16+)
03:25 Цареубийство.
 Следствие длиною в век (16+)
Следствие длиною в век (16+)Воскресенье, 30 апреля
06:00 Мультимир (6+)
07:00 И в шутку, и всерьёз (12+)
07:15 М/ф «Птицы, как мы» (6+)
08:30 Х/ф «Рок-н-ролл для принцесс» (16+)
10:55 Путешествия в деталях. Волго-Балтийский путь (12+)
11:35 Х/ф «Переписать любовь» (16+)
13:15 Х/ф «Озеро героев» (6+)
14:25 Х/ф «Вне времени» (16+)
16:05 Х/ф «Сокровища Ермака» (6+)
17:35 Х/ф «Отец поневоле» (16+)
19:05 Х/ф «Кровавая леди Батори» (16+)
20:45 Х/ф «Невероятные приключения Факира» (16+)
22:15 Х/ф «Жандарм из Сен-Тропе» (16+)
01:20 Х/ф «Золото Колчака» (16+)
02:15 Концерт Анны Герман «Эхо любви» (16+)
05:15 Федерация (16+)
Изменение формата выдачи выписки из ЕГРН с марта 2023
С 1 марта 2023 года усложнен порядок получения выписок из Единого государственного реестра недвижимости (ЕГРН). Без согласия владельца данные о жилье теперь получить будет невозможно. Таким образом законодатели рассчитывают обезопасить данные от «черных риелторов». Кто теперь обладает правом на получение выписки из ЕГРН и для чего она может понадобиться — читайте в материале «Известий».
Без согласия владельца данные о жилье теперь получить будет невозможно. Таким образом законодатели рассчитывают обезопасить данные от «черных риелторов». Кто теперь обладает правом на получение выписки из ЕГРН и для чего она может понадобиться — читайте в материале «Известий».
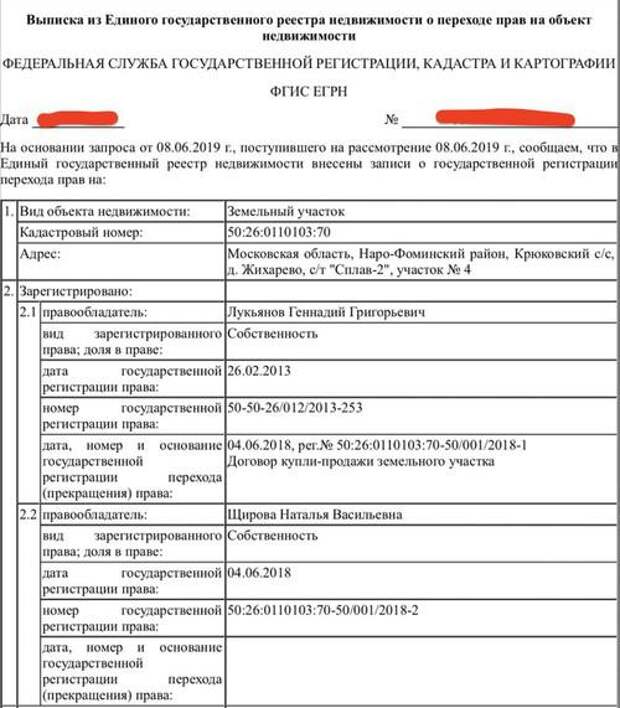
Что такое выписка из ЕГРН
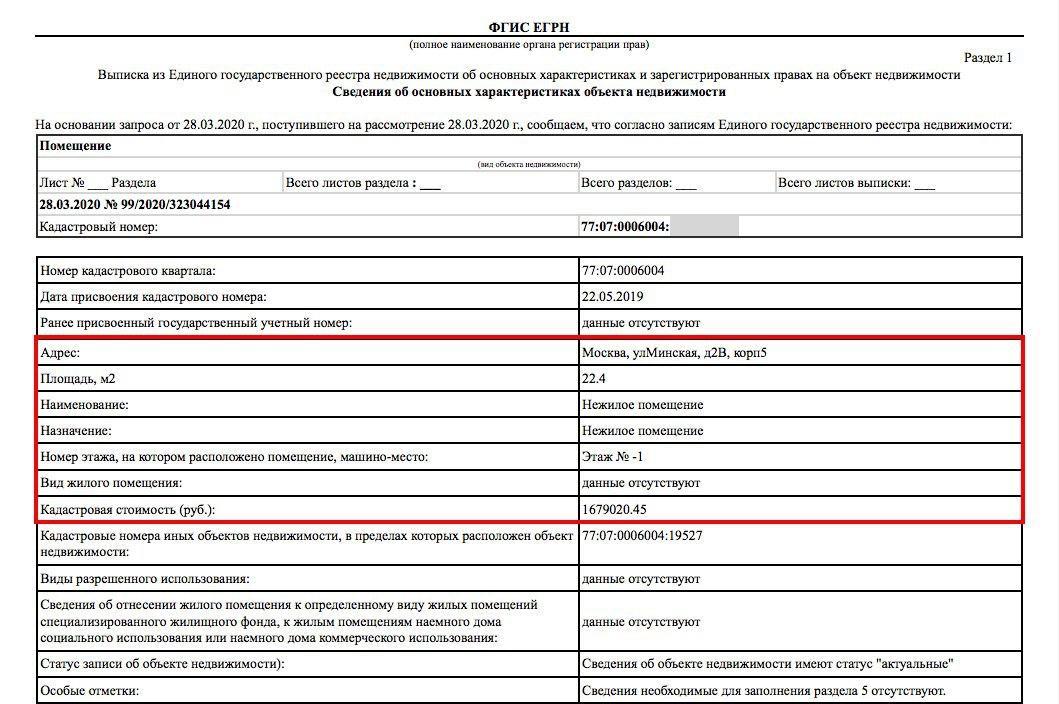
Выписка из регистра содержит информацию обо всех объектах недвижимости в России, зарегистрированных после 31 января 1998 года, в том числе, квартирах, домах, земельных участках и других объектах. Документ содержит:
- данные о прошлых и настоящих собственниках;
- кадастровые номера, площади, назначения, адреса;
- обстоятельства обременения.
Выписка из ЕГРН — неотъемлемый документ для осуществления любой сделки с недвижимостью, в том числе купли-продажи, дарения, оформления наследства. Пригодится выписка и для оформления кредита под залог недвижимости или разрешения имущественных споров.
Кто может получить выписку из ЕГРН в 2023 году
С 1 марта 2023 года получить выписку с полными данными можно будет лишь при условии согласия собственника. Посторонний человек не сможет больше узнать личные данные владельцев недвижимости. Таким образом, теперь документ со всеми сведениями сможет получить:
Посторонний человек не сможет больше узнать личные данные владельцев недвижимости. Таким образом, теперь документ со всеми сведениями сможет получить:
- владельцы и совладельцы объекта;
- супруги;
- собственники смежного участка;
- арендаторы и арендодатели;
- наследники;
- собственник участка или дома, если права собственности на эти объекты не совпадают;
- арбитражные управляющие банкротов;
- залогодержатели;
- обладатели частного и публичного сервитута на объект.
В отдельных случаях информация также может быть предоставлена представителям госорганов, нотариусам, кадастровым инженерам, в том случае, если того требует их работа.
Новый механизм вступит в силу с марта по умолчанию, но собственник всё еще может сделать данные общедоступными, подав заявление в Росреестр.
Чтобы обезопасить сделки с недвижимостью, федеральная служба также разрабатывает систему проверки выписок на достоверность по QR-коду. Пока что удостовериться в подлинности документов можно будет через нотариуса, обладающего правом на соответствующий запрос в ЕГРН.
Выписку можно заказать в электронном или бумажном варианте, а также оформить через многофункциональные центры (МФЦ).
Как получить бумажную выписку через ЕГРН
Через сайт Росреестра бумажную выписку получить нельзя — придется посещать отделение федеральной службы или МФЦ.
Причем прийти в отделение Росреестра нужно дважды: для заполнения заявления и для того, чтобы забрать документ. Стандартный срок выполнения обращения занимает три дня, но иногда получить выписку можно и в тот же день.
Через МФЦ выполнение услуги занимает больше времени — до пяти рабочих дней.
Как получить выписку из ЕГРН онлайн
Для получения электронного документа понадобится подтвержденная учетная запись на Госуслугах или электронная цифровая квалифицированная подпись со специальным расширением при оформлении через Росреестр. В заявлении необходимо указать паспортные данные и кадастровый номер недвижимости. Документ будет отображаться в личном кабинете и имеет ту же юридическую силу, что и бумажный.
Также получить выписку онлайн можно через сайт Федеральной кадастровой палаты, но для этого также понадобится учетная запись на «Госуслугах».
Ранее «Известия» писали, какие шаги нужно предпринять, чтобы как можно оперативнее осуществить сделку по продаже недвижимости.
Реклама
Как определить тип файла в Linux {+10 примеров}
Введение
Команда Linux file помогает определить тип файла и его данных. Команда не учитывает расширение файла, а вместо этого запускает серию тестов для определения типа данных файла.
В этом уроке мы покажем вам, как работает команда file и как ее использовать.
Предпосылки
- Система под управлением Linux.
- Доступ к окну терминала.
Синтаксис команды File
Команда file использует следующий основной синтаксис:
file [опция] [имя файла]
В приведенном выше синтаксисе представляет имя файла 7 вы хотите протестировать. Команда
Команда file выполняет три набора тестов, пытаясь определить тип файла, в следующем порядке:
- Тесты файловой системы выполнить системный вызов stat(2) и сравнить результат с системным заголовочным файлом. Таким образом, команда
fileопределяет, является ли файл распространенным типом для вашей системы (например, текстовый файл, изображение, каталог и т. д.). - Волшебные тесты используют короткую строку чисел, хранящуюся в начале файла («магическое число»), чтобы проверить, является ли файл исполняемым двоичным файлом, и, если да, определить его тип. Информация, необходимая для выполнения этих тестов, хранится в /etc/magic или /usr/share/misc/magic из скомпилированного файла magic.
- Языковые тесты используют специальный тег, чтобы определить, на каком языке программирования написан двоичный исполняемый файл.
Выходные данные команды содержат краткое описание файла и типа данных. Например, используя команду
Например, используя команду file для проверки текстового файла:
file example.txt
File Command Options
The файл Команда использует следующие параметры:
| Параметр | Описание |
|---|---|
| Изменяет вывод команды на тот, который используется в более ранних версиях MacOS. | |
-b, --brief | Изменяет вывод команды на краткий режим. |
-C, --compile | Создает выходной файл, содержащий предварительно проанализированную версию волшебного файла или каталога. |
-c, --checking-printout | Проверяет распечатку на проанализированную версию волшебного файла.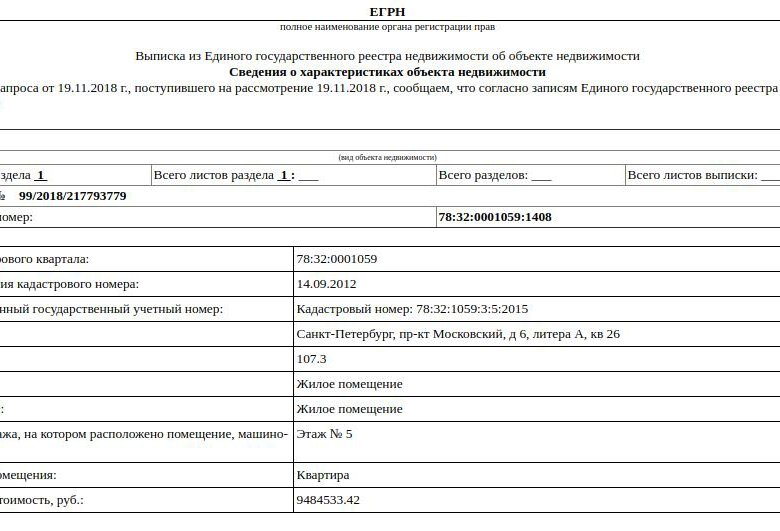 |
-d | Выводит внутреннюю отладочную информацию в стандартном формате ошибок. |
-E | При ошибке файловой системы выдает сообщение об ошибке и завершает работу. |
-e, --exclude | Исключает тест из списка тестов, выполняемых для файла. |
--exclude-quiet | Исключает тесты, о которых команда file не знает. |
--extension | Выводит список допустимых расширений для данного типа файла. |
-F, --разделитель | Использует предоставленную строку в качестве разделителя между именем файла и типом файла. |
-f, --files-from | Использует предоставленный текстовый файл в качестве списка файлов для тестирования. Список должен содержать только одно имя файла в строке. |
-h, --no-deference | Отключает переход по символическим ссылкам. |
-i, --mime | Изменяет вывод команды на строку типа MIME. |
--mime-type, --mime-encoding | Изменяет вывод команды на строку типа MIME и отображает только указанный элемент (тип или кодировку). |
-k, --keep-going | Продолжает выполнение теста после первого совпадения результатов. |
-l, --list | Показывает список совпадающих шаблонов в порядке убывания силы. |
-L, --deference | Включает переход по символическим ссылкам. |
-m, --magic-file | Использует альтернативный магический файл, предоставленный пользователем. |
-N, --no-pad | Не дополняет имена файлов, чтобы они соответствовали выходным данным. |
-n, --no-buffer | Сбрасывает вывод после проверки каждого файла. |
-p, --preserve-date | Попытки сохранить время последнего обращения к файлу, чтобы он выглядел как file Команда не проверяла его.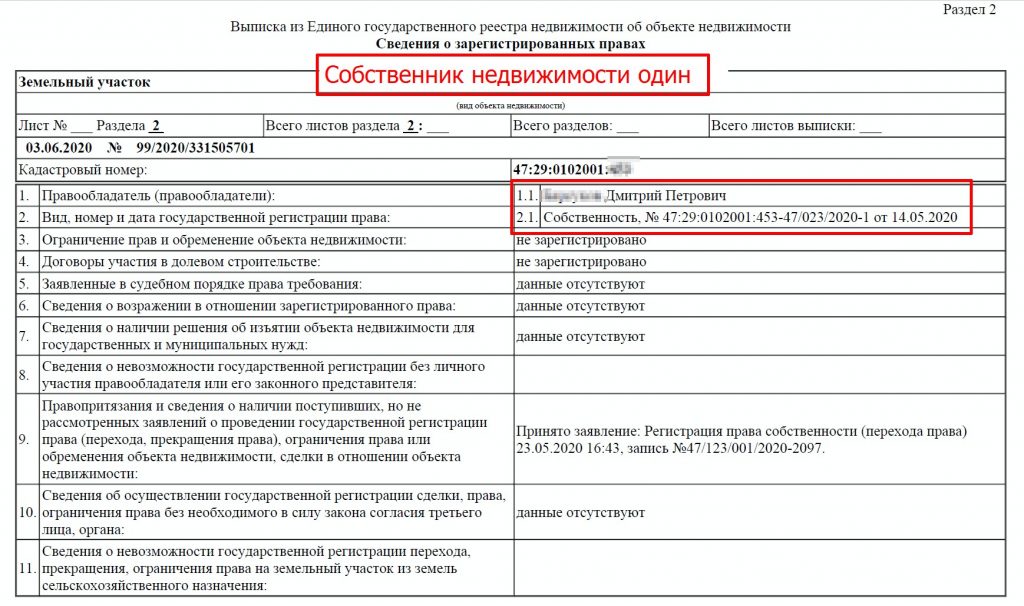 |
-P, --parameter | Устанавливает различные параметры, такие как максимальное число байтов или рекурсия, количество и предел длины. |
-r, --raw | Отключает перевод непечатаемых символов. |
-s, --special-files | Позволяет читать специальные файлы. |
-S, --no-sandbox | Отключает песочницу в системах, которые ее поддерживают. |
-v, --version | Отображает версию команды file . |
-z, --uncompress | Проверяет сжатые файлы. |
-Z, --uncompress-noreport | Проверяет сжатые файлы и отображает только тип файла без сжатия. |
-0, --print0 | Отображает нулевой символ после конца имени файла. |
--help | Отображает справочное сообщение. |
Примеры команд файла
Ниже приведены примеры распространенных вариантов использования файл команда.
Проверка нескольких файлов
Для одновременной проверки нескольких файлов добавьте имена файлов в конец команды :
файл [имя файла 1] [имя файла 2] … [имя файла n]
Например, проверка каталога, текстового файла, изображения и веб-страницы:
файл Пример example.txt0006 * ) в команду
fileдля проверки всех файлов и каталогов в текущем рабочем каталоге:file *Добавьте путь к каталогу в подстановочный знак, чтобы проверить содержимое этого каталога:
файл [путь к каталогу]/*Например, чтобы проверить содержимое каталога Example , используйте:
file Example/*Тестовые файлы в диапазоне
файл 9Команда 0007позволяет протестировать подмножество файлов в каталоге, используя диапазоны в стиле Regex. Выберите диапазон, поместив значения в скобки. Например, тестирование файлов и каталогов с именами в диапазоне от a до l:файл [a-l]*Поскольку диапазоны в стиле регулярных выражений чувствительны к регистру, выходные данные в приведенном выше примере показывают только типы файлов, начинающиеся с строчных букв a-l. Добавление другого диапазона позволяет также включать символы верхнего регистра:
файл [a-l]* [A-L]*Тестовые файлы из списка
Команда
fileпозволяет использовать текстовый файл в качестве списка файлов для тестирования.Используйте опцию
-fи добавьте путь к файлу списка вфайлкоманду:файл -f list.txtТестовые специальные файлы
5 Файл 7 команда не всегда может читать специальные файлы, например, системные файлы:файл /dev/sda5В приведенном выше примере вывод команды file показывает, что /dev/sda5 является специальным файлом блока, но не содержит дополнительных сведений. Использование параметра
-sпозволяет полностью протестировать специальные файлы:sudo file -s /dev/sda5Примечание: в сообщении об ошибке
нет разрешения на чтение. Добавитьсудов командуфайла, чтобы предотвратить это.Проверка сжатых файлов
Используйте параметр
-zдля полной проверки сжатых файлов, пытаясь определить их содержимое:-cопция отображает распечатку чека для проанализированной версии файла:файл -c example.Эта опция обычно используется с
-mопция для отладки и установки нового магического файла.Показать краткий вывод
При использовании параметра
-bотображается краткий вариант вывода. Эта версия выходных данных показывает только типы файлов и опускает имена файлов.файл -b Пример пример example.txt выхода. Например, добавьте знак плюс (+) в качестве разделителя с:файл -F + Пример example.txt sample.png index.htmlУдалить заполнение имени файла из вывода
Используйте параметр
-N, чтобы удалить заполнение между разделами имени файла и типа файла вывода:файл -N Пример example.txt уметь пользоваться линуксомфайлкоманда, чтобы узнать типы файлов в вашей системе.Если вы хотите узнать больше о командах Linux, ознакомьтесь с нашей памяткой по командам Linux.
Что такое ELMo | ELMo For text Classification in Python
Введение
Я работаю над различными задачами обработки естественного языка (NLP) (привилегии быть специалистом по данным!). Каждая проблема НЛП по-своему уникальна. Это просто отражение того, насколько сложен, прекрасен и прекрасен человеческий язык.
Но одна вещь всегда была занозой в уме практикующего НЛП — это неспособность (машин) понять истинное значение предложения. Да, я говорю о контексте. Традиционные методы и схемы НЛП отлично подходили для выполнения базовых задач. Дела быстро пошли наперекосяк, когда мы попытались добавить к ситуации контекст.
Ландшафт НЛП значительно изменился за последние 18 месяцев или около того. Фреймворки NLP, такие как BERT от Google и Flair от Zalando, способны анализировать предложения и понимать контекст, в котором они были написаны.
Вложения из языковых моделей (ELMo)
Один из крупнейших прорывов в этом отношении произошел благодаря ELMo, современной структуре НЛП, разработанной AllenNLP.
В этой статье мы рассмотрим ELMo (встраивание языковых моделей) и используем его для создания умопомрачительной модели НЛП с использованием Python на реальном наборе данных.
Примечание. В этой статье предполагается, что вы знакомы с различными типами встраивания слов и архитектурой LSTM. Вы можете обратиться к статьям ниже, чтобы узнать больше по темам:
 txt0006 * ) в команду
txt0006 * ) в команду  Текстовый файл должен содержать только одно имя файла в строке.
Текстовый файл должен содержать только одно имя файла в строке. txt
txt 
 К тому времени, как вы закончите эту статью, вы тоже станете большим поклонником ELMo, как и я.
К тому времени, как вы закончите эту статью, вы тоже станете большим поклонником ELMo, как и я. - Интуитивное понимание встраивания слов
- Основы глубокого обучения: введение в долговременную память
Содержание
- Что такое ELMo?
- Понимание того, как работает ELMo
- Чем ELMo отличается от других вложений слов? Реализация
- : ELMo для классификации текста в Python
- Понимание постановки задачи
- О наборе данных
- Импорт библиотек
- Чтение и проверка данных
- Очистка текста и предварительная обработка
- Краткое введение в TensorFlow Hub
- Подготовка векторов ELMo
- Построение и оценка моделей
- Что еще мы можем сделать с ELMo?
Что такое ELMo?
Нет, ELMo, о котором мы говорим, не персонаж из «Улицы Сезам»! Классический пример важности контекста.
ELMo — это новый способ представления слов в векторах или вложениях. Эти вложения слов полезны для достижения современных результатов (SOTA) в нескольких задачах НЛП:
ученых НЛП по всему миру начали использовать ELMo для различных задач НЛП, как в исследованиях, так и в промышленности. Вы должны ознакомиться с оригинальным исследовательским документом ELMo здесь — https://arxiv.org/pdf/1802.05365.pdf. Обычно я не прошу людей читать исследовательские работы, потому что они часто могут показаться тяжелыми и сложными, но я делаю исключение для ELMo. Это действительно классное объяснение того, как был разработан ELMo.
Понимание того, как работает ELMo
Прежде чем реализовывать его на Python, давайте интуитивно поймем, как работает ELMo. Почему это важно?
Ну, представьте себе. Вы успешно скопировали код ELMo из GitHub в Python и смогли построить модель на основе ваших пользовательских текстовых данных. Вы получаете средние результаты, поэтому вам нужно улучшить модель.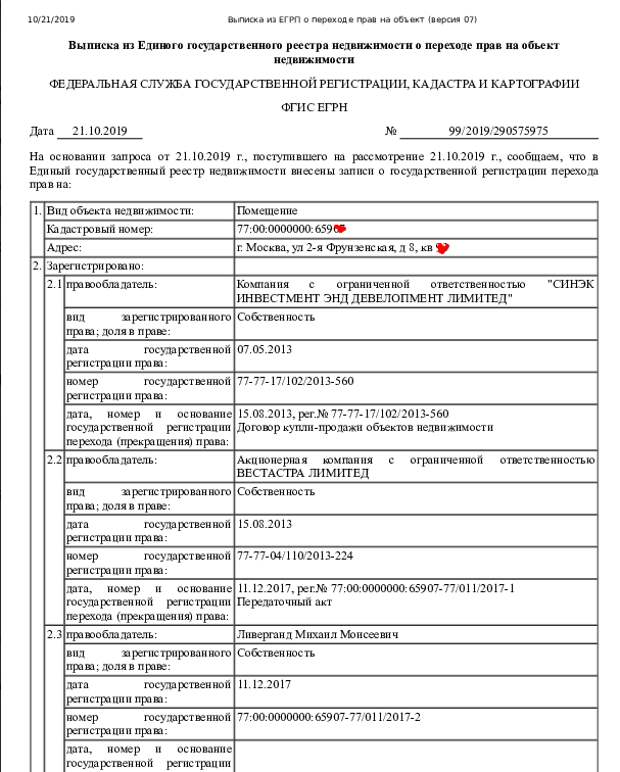 Как вы это сделаете, если не понимаете архитектуру ELMo? Какие параметры вы будете настраивать, если не изучали это?
Как вы это сделаете, если не понимаете архитектуру ELMo? Какие параметры вы будете настраивать, если не изучали это?
Это направление мысли применимо ко всем алгоритмам машинного обучения. Вам не нужно вникать в их производные, но вы всегда должны знать достаточно, чтобы поиграть с ними и улучшить свою модель.
Теперь вернемся к тому, как работает ELMo.
Как я упоминал ранее, векторы слов ELMo вычисляются поверх двухуровневой двунаправленной языковой модели (biLM). Эта модель biLM состоит из двух слоев, сложенных вместе. Каждый слой имеет 2 прохода — проход вперед и проход назад:
- В приведенной выше архитектуре используется сверточная нейронная сеть (CNN) на уровне символов для представления слов текстовой строки в необработанные векторы слов
- Эти необработанные векторы слов служат входными данными для первого уровня biLM .
- Прямой проход содержит информацию об определенном слове и контексте (других словах) перед этим словом
- Обратный проход содержит информацию о слове и контексте после него
- Эта пара информации из прямого и обратного прохода формирует векторы промежуточных слов
- Эти векторы промежуточных слов передаются на следующий уровень biLM
- Окончательное представление (ELMo) представляет собой взвешенную сумму необработанных векторов слов и 2 векторов промежуточных слов
Поскольку входные данные для biLM вычисляются из символов, а не из слов, он захватывает внутреннюю структуру слова. Например, biLM сможет вычислить такие термины, как 9.0056 красавица и красавица связаны на каком-то уровне, даже не смотря на контекст, в котором они часто появляются. Звучит невероятно!
Например, biLM сможет вычислить такие термины, как 9.0056 красавица и красавица связаны на каком-то уровне, даже не смотря на контекст, в котором они часто появляются. Звучит невероятно!
Чем ELMo отличается от других вложений слов?
В отличие от традиционных вложений слов, таких как word2vec и GLoVe, вектор ELMo, назначенный токену или слову, фактически является функцией всего предложения, содержащего это слово. Следовательно, одно и то же слово может иметь разные векторы слов в разных контекстах.
Представляю, как вы спрашиваете: как знание этого помогает мне справляться с проблемами НЛП? Позвольте мне объяснить это на примере.
Допустим, у нас есть пара предложений:
- Я прочитал книгу вчера.
- Можете ли вы прочитать письмо сейчас?
Поразмышляйте над разницей между ними. Глагол «читать» в первом предложении стоит в прошедшем времени. И этот же глагол переходит в настоящее время во втором предложении. это случай Многозначность , при которой слово может иметь несколько значений или смыслов.
И этот же глагол переходит в настоящее время во втором предложении. это случай Многозначность , при которой слово может иметь несколько значений или смыслов.
Язык — такая удивительно сложная штука.
Традиционные вложения слов дают один и тот же вектор для слова «читать» в обоих предложениях. Следовательно, система не сможет различать многозначные слова. Эти вложения слов просто не могут понять контекст, в котором слово было использовано.
словарных векторов ELMo успешно решают эту проблему. Представления слов ELMo превращают все входное предложение в уравнение для вычисления вложений слов. Следовательно, термин «чтение» будет иметь разные векторы ELMo в другом контексте.
Реализация: ELMo для классификации текста в Python
И вот долгожданный момент — реализация ELMo на Python! Давайте рассмотрим это шаг за шагом.
1. Понимание постановки задачи
Первым шагом к решению любой задачи по науке о данных является определение постановки задачи.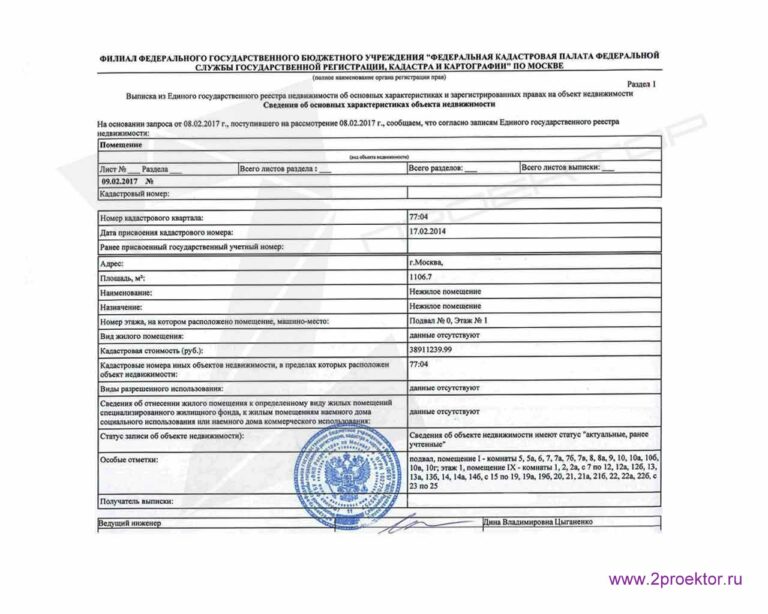 Это формирует основу для наших будущих действий.
Это формирует основу для наших будущих действий.
Для этой статьи у нас уже есть постановка задачи:
Анализ настроений остается одной из ключевых проблем, для решения которых широко применяется обработка естественного языка (NLP). На этот раз, учитывая твиты от клиентов о различных технологических фирмах, которые производят и продают мобильные телефоны, компьютеры, ноутбуки и т. д., задача состоит в том, чтобы определить, имеют ли твиты негативное отношение к таким компаниям или продуктам.
Очевидно, что это задача классификации двоичного текста, в которой мы должны предсказать настроения на основе извлеченных твитов.
2. О наборе данных
Вот разбивка имеющегося у нас набора данных:
- Набор поездов содержит 7920 твитов
- Тестовый набор содержит 1953 твита
Вы можете скачать набор данных с этой страницы. Обратите внимание, что для этого вам необходимо зарегистрироваться или войти в систему.
Осторожно: Большинство нецензурных выражений в твитах заменено на «$&@*#». Однако обратите внимание, что набор данных может по-прежнему содержать текст, который можно считать нецензурным, вульгарным или оскорбительным.
Хорошо, давайте запустим нашу любимую Python IDE и приступим к программированию!
3. Импорт библиотек
Импортируйте библиотеки, которые мы будем использовать в нашей записной книжке:
Посмотреть код на Gist.
4. Чтение и проверка данных
# чтение данных
поезд = pd.read_csv("train_2kmZucJ.csv")
тест = pd.read_csv("test_oJQbWVk.csv")
поезд.форма, тест.форма Вывод: ((7920, 3), (1953, 2))
В наборе поездов 7920 твитов, а в тестовом наборе всего 1953. Теперь давайте проверим распределение классов в наборе поездов:
.поезд ['метка'].value_counts(normalize = True)
Вывод:
0 0,744192
1 0,255808
Имя: метка, dtype: float64
Здесь 1 представляет отрицательный твит, а 0 — неотрицательный твит.
Давайте быстро взглянем на первые 5 строк в нашем наборе поездов:
Код Python:
У нас есть три столбца для работы. Столбец «твит» является независимой переменной, а столбец «ярлык» — целевой переменной.
5. Очистка и предварительная обработка текста
В идеальном мире у нас был бы чистый и структурированный набор данных для работы. Но в НЛП все не так просто (пока).
Нам нужно потратить значительное количество времени на очистку данных, чтобы подготовить их к этапу построения модели. Извлечение функций из текста становится простым, и даже функции содержат больше информации. Вы увидите значительное улучшение производительности вашей модели по мере улучшения качества ваших данных.
Итак, давайте очистим текст, который нам дали, и изучим его.
Кажется, в твитах довольно много URL-ссылок. Они мало что говорят нам (если вообще что-то говорят) о настроении твита, поэтому давайте их удалим.
Посмотреть код на Gist.
Мы использовали регулярные выражения (или RegEx) для удаления URL-адресов.
Примечание: Вы можете узнать больше о Regex в этой статье .
Сейчас мы продолжим и выполним рутинную очистку текста.
Посмотреть код на Gist.
Еще хотелось бы нормализовать текст, ака, выполнить нормализацию текста. Это помогает сократить слово до его основной формы. Например, основная форма слов «производство», «производство» и «производство» — «продукт» . Довольно часто бывает, что несколько форм одного и того же слова на самом деле не так важны, и нам нужно знать только основную форму этого слова.
Мы лемматизируем (нормализуем) текст, используя популярную библиотеку spaCy.
Посмотреть код на Gist.
Лемматизировать твиты как в поезде, так и в тестовом наборе:
поезд ['clean_tweet'] = лемматизация (поезд ['clean_tweet']) тест ['clean_tweet'] = лемматизация (тест ['clean_tweet'])
Давайте быстро сравним исходные твиты с нашими очищенными:
поезд.
 образец(10)
образец(10) Внимательно ознакомьтесь с приведенными выше столбцами. Твиты в столбце «clean_tweet» кажутся более разборчивыми, чем исходные твиты.
Тем не менее, я чувствую, что есть еще много возможностей для очистки текста. Я призываю вас изучить данные как можно больше и найти больше идей или несоответствий в тексте.
6. Краткое введение в TensorFlow Hub
Подождите, какое отношение TensorFlow имеет к нашему туториалу?
TensorFlow Hub — это библиотека, которая обеспечивает перенос обучения, позволяя использовать множество моделей машинного обучения для разных задач. ELMo — один из таких примеров. Вот почему в нашей реализации мы будем получать доступ к ELMo через TensorFlow Hub.
Прежде чем делать что-либо еще, нам нужно установить TensorFlow Hub. Вы должны установить или обновить пакет TensorFlow как минимум до версии 1.7, чтобы использовать TensorFlow Hub:
.$ pip install "tensorflow>=1.
 7.0"
$ pip установить тензорный поток-концентратор
7.0"
$ pip установить тензорный поток-концентратор 7. Подготовка ELMo Vectors
Теперь мы импортируем предварительно обученную модель ELMo. Обратите внимание: размер модели превышает 350 МБ, поэтому ее загрузка может занять некоторое время.
импортировать tensorflow_hub как концентратор
импорт тензорный поток как tf
elmo = hub.Module("https://tfhub.dev/google/elmo/2", trainable= True ) Сначала я покажу вам, как мы можем получить векторы ELMo для предложения. Все, что вам нужно сделать, это передать список строк в объекте elmo .
Посмотреть код на Gist.
Вывод: TensorShape([Dimension(1), Dimension(8), Dimension(1024)])
Выход представляет собой трехмерный тензор формы (1, 8, 1024):
- Первое измерение этого тензора представляет количество обучающих выборок. Это 1 в нашем случае
- Второе измерение представляет собой максимальную длину самой длинной строки во входном списке строк. Так как у нас есть только 1 строка в нашем списке ввода, размер 2-го измерения равен длине строки — 8
- Третье измерение равно длине вектора ELMo
 Так как у нас есть только 1 строка в нашем списке ввода, размер 2-го измерения равен длине строки — 8
Так как у нас есть только 1 строка в нашем списке ввода, размер 2-го измерения равен длине строки — 8Следовательно, каждое слово во входном предложении имеет вектор ELMo размера 1024.
Давайте продолжим и извлечем векторы ELMo для очищенных твитов в наборах данных поезда и теста. Однако, чтобы получить векторное представление всего твита, мы возьмем среднее значение векторов ELMo составляющих терминов или токенов твита.
Давайте определим функцию для этого:
Посмотреть код на Gist.
У вас могут закончиться вычислительные ресурсы (память), если вы используете вышеуказанную функцию для извлечения вложений для твитов за один раз. В качестве обходного пути разделите обучающий и тестовый наборы на партии по 100 образцов в каждой. Затем последовательно передать эти пакеты в функцию elmo_vectors() .
Я буду хранить эти партии в списке:
list_train = [train[i:i+100] для i в диапазоне (0,train.
 shape[0],100)]
list_test = [test[i:i+100] для i в диапазоне (0,test.shape[0],100)]
shape[0],100)]
list_test = [test[i:i+100] для i в диапазоне (0,test.shape[0],100)] Теперь мы пройдемся по этим пакетам и извлечем векторы ELMo. Предупреждаю, это займет много времени.
# Извлечение вложений ELMo elmo_train = [elmo_vectors(x['clean_tweet']) для x в list_train] elmo_test = [elmo_vectors(x['clean_tweet']) для x в list_test]
Когда у нас есть все векторы, мы можем объединить их обратно в один массив:
elmo_train_new = np.concatenate (elmo_train, ось = 0) elmo_test_new = np.concatenate (elmo_test, ось = 0)
Я бы посоветовал вам сохранить эти массивы, так как нам потребовалось много времени, чтобы получить для них векторы ELMo. Мы сохраним их как файлы рассола:
Посмотреть код на Gist.
Используйте следующий код, чтобы загрузить их обратно:
Посмотреть код на Gist.
8. Построение и оценка моделейДавайте построим нашу модель НЛП с помощью ELMo!
Мы будем использовать векторы ELMo из набора данных поезда для построения модели классификации. Затем мы будем использовать модель для прогнозирования тестового набора. Но перед всем этим разделите elmo_train_new на наборы для обучения и проверки, чтобы оценить нашу модель до этапа тестирования.
Затем мы будем использовать модель для прогнозирования тестового набора. Но перед всем этим разделите elmo_train_new на наборы для обучения и проверки, чтобы оценить нашу модель до этапа тестирования.
Посмотреть код на Gist.
Поскольку наша цель — установить базовую оценку, мы построим простую модель логистической регрессии, используя векторы ELMo в качестве признаков:
Посмотреть код на Gist.
Время предсказаний! Во-первых, на проверочном наборе:
preds_valid = lreg.predict(xvalid)
Мы будем оценивать нашу модель по метрике очков F1, так как это официальная метрика оценки конкурса.
f1_score(yvalid, preds_valid)
Вывод: 0,789976
Оценка F1 на проверочном наборе впечатляет. Теперь продолжим и сделаем прогнозы на тестовом наборе:
.# делать прогнозы на тестовом наборе preds_test = lreg.predict(elmo_test_new)
Подготовьте файл заявки, который мы загрузим на страницу конкурса:
Посмотреть код на Gist.
Эти прогнозы дают нам 0,875672 очков в общедоступной таблице лидеров. Честно говоря, это впечатляет, учитывая, что мы выполнили только базовую предварительную обработку текста и использовали очень простую модель. Представьте, какой счет мог бы быть с более продвинутыми методами. Попробуйте их со своей стороны и дайте мне знать о результатах!
Что еще мы можем сделать с ELMo?
Мы только что воочию убедились, насколько эффективным может быть ELMo для классификации текста. В сочетании с более сложной моделью это, безусловно, даст еще лучшую производительность. Применение ELMo не ограничивается только задачей классификации текстов. Вы можете использовать его всякий раз, когда вам нужно векторизовать текстовые данные.
Ниже приведены еще несколько задач НЛП, в которых мы можем использовать ELMo:
- Машинный перевод
- Языковое моделирование
- Обобщение текста
- Распознавание именованных объектов
- Системы вопросов-ответов
Конец Примечания
ELMo, несомненно, представляет собой значительный прогресс в НЛП, и он никуда не денется.